-
[강화학습] 강화학습의 기본개념[Study] Data Science/머신러닝&딥러닝 2021. 12. 26. 22:32
강화학습의 특징
- label이 없고(=supervisor가 없음), reward에 의존하여 학습한다→ 전체적인 미래의 보상을 최대화하는 행동을 선택하는 것이다.
- reward는 그 환경에 따라 즉각적으로 나타날 수도, 그렇지 않을 수도 있다 → 즉, 장기적인 보상을 위해서 단기적인 보상을 희생하게 될 수도 있다.
- Agent의 행동은 다음의 reward에 영향을 미친다.
주요 개념
1) History : observations, actions, rewards의 연속적인 데이터

2) State : 다음 step에서 일어날 일을 결정하기 위해 활용되는 정보로, 관찰 가능한 상태의 집합이다. 히스토리에 대한 함수라고 할 수 있다.

① Environment State : agent에게는 보이지 않는 환경으로 전체적인 환경이라고 이해할 수 있다.
* 우리가 우리를 둘러싸고 있는 환경 전체에 대해 모두 알 수 없듯, agent도 환경의 전체를 파악할 수 없다.
② Agent State : agent가 관찰 가능한 상태의 집합으로, 다음 행동을 결정하는데 사용하는 정보이다.
* 강화학습 알고리즘에 사용되는 정보이기도 하다.
③ Markov State : 히스토리의 모든 유용한 정보를 포함하고 있는 state이다.

- Markov State는 위의 수식과 같이 표현할 수 있는데, St가 일어난 상태에서 St+1가 발생할 확률과 최초의 State S1에서 출발해서 step t의 State St까지 일어난 상태에서 St+1가 발생할 확률은 같다는 의미다.
- 이는 현재의 state St가 미래를 결정할 수 있을만큼의 충분한 정보를 보유하고 있다는 뜻으로, St가 이전의 히스토리의 정보를 충분히 담고 있다는 것과 같다.
- 즉, 현재의 상태 St가 과거의 정보를 가지고 있기 때문에, 더 과거의 정보들은 사실상 필요가 없다.
[참고]
※ Full Observability : agent가 environment state를 모두 관찰할 수 있는 상태
* environment state == agent state == Markov state
* 이러한 상태를 Markov Decision Process(MDP)로 정의할 수 있다.
※ Partially Observable Environment : agent가 environment state를 부분적으로 관찰할 수 있는 상태
* environment state != agent state
* agent는 자체적으로 현재 시점의 state을 구축해야 한다.
* 이러한 상태를 Partially Observable Markov Decision Process(POMDP)로 정의할 수 있다.3) action: 에이전트가 상태 St에서 할 수 있는 가능한 행동의 집합
4) reward function: 흔히 보상이라고 하며, 환경이 에이전트에게 주는 정보
상태 s에서 행동 a를 했을 경우에 받을 보상에 대한 기댓값이라고도 할 수 있다. 이 때 기댓값이라고 표현하는 이유는 같은 상태에서 같은 행동을 취하더라도, 다른 보상을 줄 수도 있기 때문이다. 또한 특정 상태에서 행동을 한 것은 t시점이지만, 보상을 받는 시점은 t+1시점이라는 점을 유의해야 한다.

상태가 St = s, 행동이 At=a일 때, 에이전트가 받을 보상
Major Component of an RL Agent (Agent가 주의를 기울이는 구성요소들)
*이 구성요소들은 반드시 포함되어야하는 것은 아니며, 강화학습 알고리즘에 따라 다르다.
1) Policy : agent가 행동을 선택하는 규칙, 상태가 입력으로 들어오면 어떤 행동을 할지를 출력해주는 함수
① Deterministic Policy : 동일한 state에서 항상 동일한 action을 취하는 경우, π(s) → a
② Stochastic Policy : 동일한 state이더라도, 일정한 확률에 의해 action을 취하는 경우
* 특정 상태에서 어떤 행동을 하는 것이 확률적으로 높은지를 살펴보고, 확률이 높은 쪽으로 행동을 취함

agent는 강화학습을 통해 단순한 정책이 아니라, 최적의 정책을 찾아야 한다. 학습 시에는 확률적으로 여러 행동을 선택해 봄으로써 다양한 상황에 대해 학습하게 될 것이며, 결과적으로 각 상태에서 최적의 결과를 낳는 하나의 행동을 선택할 수 있어야 한다.
2) Value Function : 미래에 축적될 보상에 대한 예측치로, state의 좋고 나쁨을 평가하는데 사용

- 에이전트가 실제로 환경을 탐험하며 받은 보상들의 합을 반환값(Return, Gt)이라고 한다.
- 하지만 반환값은 에피소드가 끝난 후에만 알 수 있기 때문에, 정확하지는 않더라도 앞으로 얼마만큼의 보상을 받을 것인지를 기댓값을 통해 예측해볼 수 있을 것이다.
- 따라서 특정한 Policy가 주어져 있는 State에서의 value는 바로 다음 step에서 즉각적으로 일어날 보상과 그 이후의 보상들의 기댓값으로 정의할 수 있으며, 이를 가치함수(value function)이라고 한다.
- 이 때, 미래의 보상에 대해서는 gamma(할인율)을 적용하여 계산한다.
- 즉, 미래에 기대되는 보상을 파악하고, 그 보상의 기댓값을 비교하여 다음에 어떤 상태로 가야할지 판단한다.
- 각 state에 대한 value function(가치함수)를 구해서, 가장 가치가 큰 state쪽으로 움직인다.
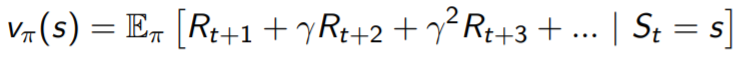


3) Q-function
- value function을 통해 다음에 어떤 상태로 갈지를 결정할 수 있지만, 그 상태로 가기 위한 행동은 다시 한 번 판단해야한다.
- 만약, 특정 상태에서 각 행동에 대한 가치함수를 별도로 만든다면 위와 같은 점을 보완할 수 있을 것이다.
- Q-function이란 어떤 상태에서 어떤 행동이 얼마나 좋은지를 알려주는 함수로, 행동가치함수라고도 한다.

- q함수와 가치함수 간의 관계는 아래와 같이 표현가능하다.

4) Model : 환경이 다음에 행하게 될 행동을 예측하는 것으로, 환경이 agent에게 제공할 정보라고 이해가능함
- 환경은 크게 상태전환과 보상액 결정을 담당한다.
- P : 어떤 State s에서 특정한 action을 했을 때, s'로 갈 확률 = transition probability(상태변환확률)
- R : 어떤 State s에서 특정한 action을 했을 때, 얻어지는 보상의 기댓값

Learning & Planning
1) Planning
- 모델의 환경이 이미 알려져 있는 상태
- agent가 환경과 직접적인 상호작용을 한다기보다는 계산을 통해서 문제를 해결하는 경우
2) Reinforcement Learning
- 환경이 알려져 있지 않은 상태
- agent가 환경과 상호작용을 해나가면서 학습해나가는 경우
- 경험을 토대로 policy를 개선함
Exploration & Exploitation
1) Exploration
- 시행착오를 통해 학습하고, 더 나은 policy를 발견해 나가는 행위
- 탐험을 너무 많이 하게 되면 학습 시간이 지연되기도 하지만, 탐험을 하지 않게 되면 더 나은 방향으로 학습할 수 있는 기회를 놓쳐버리게 되므로 exploration과 exploitation간 균형이 중요
2) Exploitation
- 이미 얻어진 정보를 활용하여 궁극적인 reward를 극대화하는 것
※ 출처 : https://www.davidsilver.uk/teaching/ 강의노트
'[Study] Data Science > 머신러닝&딥러닝' 카테고리의 다른 글
[강화학습] Model Free Prediction: Monte-Carlo, Temporal Difference, SARSA (0) 2022.01.05 [강화학습] Model-based Planning by Dynamic Programming (0) 2021.12.31 [강화학습] Markov Decision Process(MDP) (0) 2021.12.27 XGBoost 알고리즘 (0) 2021.11.06 추천시스템의 기본 알고리즘 (0) 2021.03.11