-
추천시스템의 기본 알고리즘[Study] Data Science/머신러닝&딥러닝 2021. 3. 11. 19:51
오늘은 추천시스템의 기본 알고리즘인 콘텐츠 기반 필터링(Content based Filtering)과 협업 필터링(Collaborative Filtering)에 대해 정리해보고자 한다.
1. 콘텐츠 기반 필터링(Content based Filtering)
콘텐츠 기반 필터링은 "사용자가 특정한 아이템을 선호할 때, 해당 아이템과 유사한 다른 아이템을 추천"하는 방식이다.
예를 들어, 사용자가 A라는 영화에 좋은 평점을 부여했다고 가정하자. 영화A의 특징을 추출하자면, 000감독의 액션장르 영화이다. 그렇다면 사용자에게는 A와 유사한 000감독의 또 다른 영화인 B를 추천해주는 것이다.
- 장점 : 다른 사용자의 데이터가 필요하지 않고, 추천할 수 있는 아이템의 범위가 넓다.
- 단점 : 기록이 없는 신규 사용자의 경우 추천이 어렵고, 유사한 특성을 가진 아이템을 반복 추천하므로 다양한 취향의 반영이 어렵다.
■ TF-IDF를 활용한 컨텐츠 기반 필터링
추천하는 아이템이 영화라고 한다면, 영화의 특징(ex. 영화제목, 장르, 영화, 출연진 등)은 많은 부분 텍스트 데이터로 이루어져 있을 것이다. TF-IDF(Term Frequency-Inverse Document Frequency) 벡터를 계산함으로써 각 아이템 간의 유사도를 구할 수 있다.
1) TF-IDF의 개념-
TF(Term Frequency) : 특정 단어의 등장 빈도 (특정 단어의 등장 횟수 / 문서 내 총 단어 수)
- DF(Document Frequency) : 특정 단어가 등장하는 문서의 수 (특정 단어가 등장하는 문서의 수/ 전체 문서의 수)
- IDF(Inverse Document Frequency) : DF의 역수
- TF-IDF = TF*IDF
TF*IDF값은 특정 문서 내에서 단어 빈도가 높을 수록(TF 값이 클수록), 전체 문서들엔 그 단어를 포함한 문서가 적을 수록(DF값이 작을 수록) TF-IDF 값이 커지게 된다. 따라서 TF-IDF를 통해 문서 내에서 특정 단어가 가지는 중요도를 알 수 있게 된다.
만약 특정 단어 t가 모든 문서에 다 등장하는 흔한 단어라면(=DF가 큼, 중요도가 낮음), 그 역수인 IDF를 곱함으로써 tf-idf 가중치를 낮춰주려는 것이라고 볼 수 있다.
2) 적용
- 아이템 간의 TF-IDF 값을 표기한 TF-IDF 행렬을 구한다. 파이썬의 경우 TfidfVectorizer를 사용할 수 있다.
from sklearn.feature_extraction.text import TfidfVectorizer- 코사인 유사도를 통해서 아이템 간 유사도를 구한다.
from sklearn.metrics.pairwise import cosine_similarity
2. 협업필터링(Collaborative Filtering)
협업필터링은 사용자-아이템 평점 매트릭스 등과 같이 사용자의 행동 데이터를 기반으로 아직 평가하지 않은 아이템을 예측평가하는 것이다. 협업필터링은 다시 '최근접 이웃 협업필터링'과 '잠재요인 협업필터링' 방식으로 구분할 수 있다.
2.1 최근접 이웃 협업필터링
최근접 이웃 협업필터링은 쉽게 말해, 사용자와 취향이 비슷한 다른 사용자가 어떤 것을 선택했는지를 참고하는 방식이라고 할 수 있다.
■ 사용자 기반 최근접 이웃 협업필터링
" 당신과 비슷한 고객이 이러한 상품을 구매했습니다"
사용자 기반(User-User)의 최근접이웃 협업필터링은 특정 사용자와 유사한 다른 사용자 중 상위 n명을 선정하여, 상위 n명이 선호하는 아이템을 추천하는 방식이다.
아래와 같이 사용자-아이템 평점 행렬이 있다고 가정하자.
각 아이템들에 대해 사용자들이 부여한 평점 정보를 볼때, <사용자 A-사용자B>가 <사용자A-사용자C>보다 유사한 취향을 가지고 있음을 확인할 수 있다.
이 때, A와 취향이 유사한 B가 해리포터에 좋은 평점을 부여했으므로, 해리포터를 아직 보지 않은 A에게 해리포터를 추천하는 방식이다.

사용자 기반 최근접 이웃 협업필터링 ■ 아이템 기반 최근접 이웃 협업필터링
"이 상품을 선택한 다른 고객들은 저 상품도 구매했습니다"
사용자들의 아이템 선호도에 따라 평가척도가 유사한 아이템을 추천하는 알고리즘이다.
아래의 행렬에서 노트북과 어바웃타임에 대한 사용자 평점이 가장 유사하므로, 노트북을 보지 않은 사용자 D에게 노트북과 유사한 어바웃타임을 추천해주는 것이다.
이 때, 유사도 계산은 주로 코사인 유사도를 사용한다.
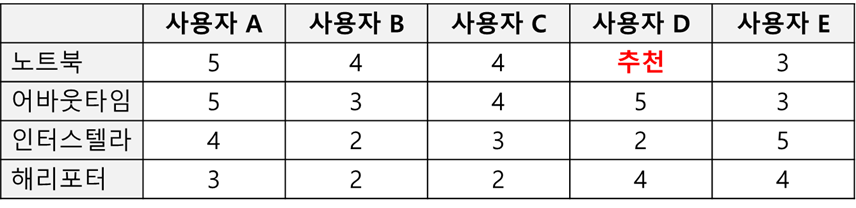
아이템 기반 최근접이웃 협업필터링 예시
2.2 잠재요인 협업 필터링
잠재요인 협업 필터링은 사용자-아이템 평점 매트릭스 속에 숨어있는 잠재 요인을 추출해 예측하는 기법이다. (이 때 '잠재요인'은 명확히 정의할 수 없다.)
좀 더 구체적으로 말하자면 다차원의 희소행렬인 사용자-아이템 평점 매트릭스를 저차원의 밀집행렬로 행렬분해(Matrix Factorization)를 하고, 분해된 행렬 간의 내적 곱을 통해 예측 평점을 도출한다.
아래의 그림에서 사용자-아이템 평점행렬 R의 (1,1)에는 user1이 item1에 대해 부여한 4점의 평점 데이터가 있다. 이는 행렬 분해와 내적 곱 과정을 거친 "P의 User1에 대한 백터와 Q.T(Q의 전치행렬)의 Item1에 대한 벡터를 곱한 값"으로 유사하다. 즉 이러한 원리를 통해, 사용자가 평가하지 않은 아이템에 대한 평점을 포함해 사용자-아이템 평점 행렬의 모든 평점 값은 행렬 분해를 통해 나온 P와 Q.T 행렬의 내적곱을 통해 나온 값으로 예측할 수 있게 되는 것이다.

행렬분해 예시 > 출처: https://velog.io/@wow-kim/ML추천시스템 행렬 분해 시에는 주로 SVD(Singular Value Decomposition)를 활용한다. 그러나 SVD는 Null값이 없는 행렬에 대해서만 적용할 수 있기 때문에, 이러한 단점을 보완하고자 확률적 경사 하강법이나 ALS(Alternative Least Square) 방식을 접목하여 SVD를 수행한다.
■ 확률적 경사 하강법을 이용한 행렬분해
P와 Q.T행렬로 계산된 예측행렬 R ̂이 실제행렬 R과 가장 최소의 오류를 갖게 하는 최적의 P와 Q를 유추해나는 것이다.
- P와 Q를 임의의 값을 가진 행렬로 설정한다.
- P와 Q.T 값을 통해 예측행렬 R ̂을 계산하고, R 과의 차이(오차)를 계산한다.
- 오차를 최소화할 때까지 P와 Q를 업데이트한다.
수식으로 표현하면 아래와 같다.
실제값과 예측값 간의 오류를 최소화하면서, 과적합을 방지위해 L2규제가 사용되었다.

- R_((u,i)) : 실제행렬 R의 u행 i열에 위치한 값
- P_(u) : 행렬 P의 사용자 u행 벡터
- Q_(i)^t : 행렬 Q의 아이템 i행의 전치 벡터
- R ̂_((u,i)) : P_(u) * Q_(i)^t , 예측행렬 R ̂ 의 값
'[Study] Data Science > 머신러닝&딥러닝' 카테고리의 다른 글
[강화학습] Model Free Prediction: Monte-Carlo, Temporal Difference, SARSA (0) 2022.01.05 [강화학습] Model-based Planning by Dynamic Programming (0) 2021.12.31 [강화학습] Markov Decision Process(MDP) (0) 2021.12.27 [강화학습] 강화학습의 기본개념 (0) 2021.12.26 XGBoost 알고리즘 (0) 2021.11.06